Feedback Loops
Feedback loops are crucial when trying to modify a system or build something new. Engineers can only safely move as fast as their comprehension of how a change impacts a system. The abilities and limitations of how computers and humans process information is massively important here; including how feedback information is stored, retrieved, and presented to systems and engineers.
Table of Contents
- What Is A Feedback Loop?: Breaks down what feedback loops are and how they tie into lean sofware development methodology.
- Mistake-Proofing, Build Pipelines and Feedback Loops: Explains what mistake proofing is and how build pipelines create feedback loops.
- Attributes of High Quality Feedback: Describes what separates good feedback signals from bad and what are the attributes of high quality feedback.
- Technical Practices That Enable High Quality Feedback: Gives you software development practices you can use to improve your use of automated checks and tests in your workflow and build pipeline.
If you’re experienced with continuous integration and developing unit and integration tests then some of this might seem familiar but this article should add breadth and depth to your intuition. We will break down why automated feedback is valuable and how we can go about quantifying which feedback is the most beneficial and useful.
There are three primary automated feedback mechanisms when building and deploying software:
- Monitoring checks.
- Static code analysis.
- Automated tests.
Results from these mechanisms are sent out to teams while they iteratively build, deploy, and run systems in a process that forms a feedback loop.
What Is A Feedback Loop?
It’s the feedback that occurs when outputs of a system are routed back as inputs in a chain of cause-and-effect that forms a loop.
They are used in some iterative improvement cycles such as:
Tracer-Bullet Development
An iterative software development process that emphasizes implementing small vertical slices of a system and getting feedback early. This is similar to doing a “technical spike” where you implement a few steps of a purposed feature to receive feedback, expose any unknowns in the code and architecture, and incrementally add functionality with each vertical slice of an implementation. [1]
Tracer Bullet Development is based on the idea of taking some single feature, single action, single thread of workflow, and implementing it all the way through the system under construction: from UI to database, passing through any middle layers right from the very first implementation on the first day. None of these layers need to be fully functional, but they must be present. Think of it as an extended “Hello, World!” programming exercise. - Andy Hunt, Pragmatic Programmer
These vertical slices of implementation are the tracer bullets. Tracer bullets are rounds that illuminate like a flare and help guide a gunners aim.
A coding example of this could be adding method “stubs” that return some dummy data or “not implemented” exceptions and gradually filling them in with functionality as needed.
Another example is if your building a web service, start by creating an HTTP endpoint that will respond with an HTTP 200 and simple string like “good” which you can use as a health check. To implement this it would require you to get the basics of your web application framework and server configured, but once you have basics working, this code can now serve as a basic monitoring health check and is a good starting point to start adding more functionality.
BML: Build, Measure, Learn.
A popular lean, iterative development and feedback process. It can be broken down into the following sequence:
- Building a feature or product. Usually, only a small slice is done at first as an M.V.P.(Minimal Viable Product).
- Measure consumer feedback and utilization metrics.
- Learn from the feedback and metrics to better respond to emerging consumer wants and needs
These processes become loops since you should generally go back to step one after each iteration by building something again with improved insight.
Put simply:
Change something
Find out how it went
Learn from it
Change something again. [2]
Mistake-Proofing, Build Pipelines and Feedback Loops
Continuous Integration and Continuous Delivery(CI/CD) pipelines are crucial in the iterative development and improvement of software. Continuous delivery treats a deployment pipeline as a “Lean Poka-Yoke”, which is a process where code must go through a set of validations on its way to release.
Poka-Yoke is a Japanese term for a mistake-proofing methodology that is used to help prevent operators from making mistakes in lean manufacturing. The methodology works well in other contexts, such as continuous delivery, since a deployment pipeline can verify that a change is safe before deploying it. There are two types of processes in mistake proofing:
- Warning Process: A cautionary alert to warn an operator of a potential mistake. These are usually non-blocking. Examples in software development include:
- Compiler warnings.
- Deprecation notices.
- Monitoring alerts that warn but don’t trigger high-severity incidents.
- Control Process: A strict process that is designed to guarantee an issue doesn’t reappear. These are usually blocking. Examples in software development include:
- Protected branches in GitHub that block merges unless certain conditions pass.
- Reliable automated tests in a build pipeline that block a deploy.
- Compiler errors.
- Pro-actively throwing exceptions to prevent a destructive operation.
- Monitoring alerts that automatically trigger corrective action.
A CI/CD pipeline is a software build and delivery process where changes go through sequential steps to build, test an deploy. They both serve as mistake-proofing process and as a feedback mechanism.
Even more broadly, a pipeline can be modeled as a “Directed Acyclic Graph” (DAG); which is a directed graph with finite nodes and no cycles. Each step in the build process is a node(circle), and the directed edges(connections) lead the code to its next sequential step.
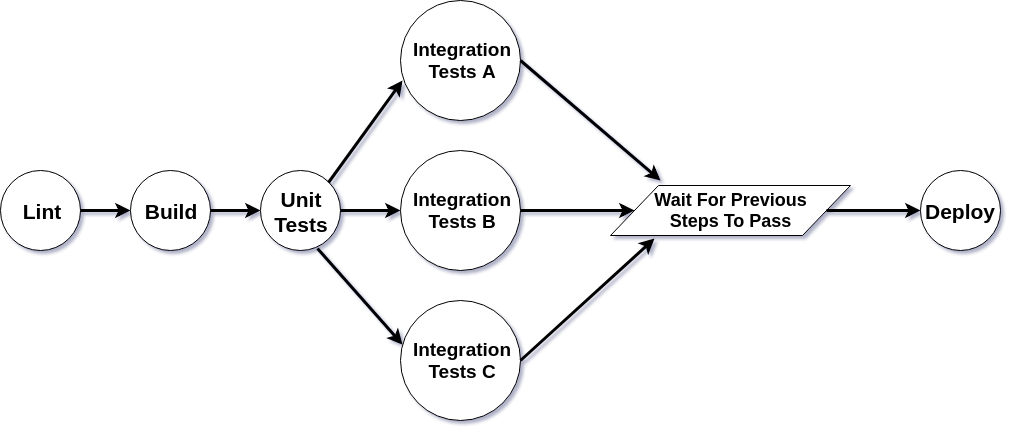
The reason there are no cycles is that if the code fails at any step and needs to be corrected, the newly modified code initiates a brand new pipeline build and must start over from the beginning. The code must proceed through the directed order and cannot arbitrarily move between steps.
If a software change fails at any of these steps, the process stops, and an indicator of the failing step gets shown in a build dashboard, a chat room, and the result can be reported as a failing “check” in a pull request that’ll block it from being merged. While an individual build of the pipeline itself isn’t exactly a cycle, the results of each step are fed back to the people modifying the system, and they use this information to guide subsequent changes. Forming a feedback cycle that looks like below:
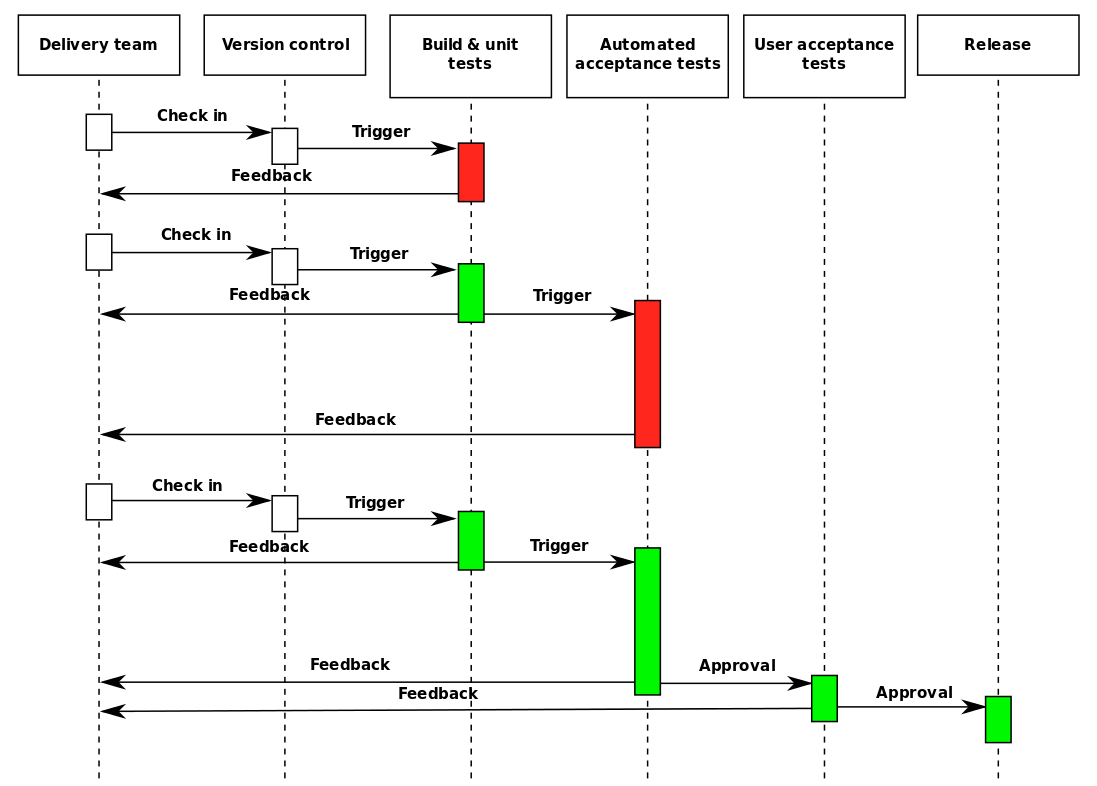
This creates a feedback loop known as a “build cycle”. Each cycle feeds the next with more clarity into what’s happening in the system.
With each build and deploy, we get results.
With those results, we learn and gain visibility into what we should improve.
With our improved understanding from this learning, we make another change starting the cycle over again.
Then another cycle, again, again, and again. Iteratively building, improving, and adjusting to arising circumstances.
Pipelines enable a “virtuous cycle” of iterative development and improvement.
Most iterative development and improvement systems emphasize measurement, learning, and thoughtful improvement. Feedback signals are needed for measurement and learning. These signals can potentially inform us if something is correct or incorrect. While that alone seems helpful, it’s almost worthless if the individuals don’t understand where and why the failures are happening. Further effort is still needed to fix and improve the problems that surface in order to capitalize on the value of this feedback.
Feedback alone isn’t enough; it can be confusing and even harmful if it overwhelms our brains’ ability to process it. For us to have efficient build cycles, we must ensure the feedback from our build cycles and elsewhere is high quality. So what makes feedback high quality?
Attributes of High Quality Feedback
Useful feedback is about more than is something right or wrong.
High quality feedback is feedback that is:
- Clear and Meaningful: Feedback that’s understandable and meaningful for the type of change that is being evaluated.
- Accurate: Feedback that correctly assesses a situation. Examples include:
- Tests that execute the needed code paths.
- Monitoring checks that measure status correctly.
- Reliable: Feedback results that are consistent. Examples include
- Deterministic tests.
- Builds and monitoring alerts that are not flaky.
- Relatively Fast: Feedback that’s received reasonably quickly after a change is made. Examples include:
- Monitoring alerts that report status quickly after detecting an anomaly.
- Unit tests that take less than a few seconds to execute.
- Integration tests that leverage concurrency to speed up execution time.
Low quality feedback is feedback that is:
- Unclear and Meaningless: Feedback that’s confusing and isn’t useful for the change being evaluated. Examples include:
- Tests that report failures with extremley verbose errors and logs that are hard to read
- Monitoring alerts that include irrelevant details as to where an issue is.
- Inaccurate: Feedback that doesn’t correctly evaluate a situation. Examples include:
- Tests that incorrectly state a failure is one part of the code when it’s in another.
- Monitoring alerts that trigger for non-existent issues.
- Unreliable: Feedback results that are inconsistent. Examples include:
- Indeterministic and flakey tests.
- Monitoring checks that only correctly fire sometimes.
- Relatively Slow: Feedback that’s received a long time after a change is made. Examples include:
- Unit tests that take over a minute to run.
- Monitoring alerts that report a failure a long time after an anomaly is detected.
- Integration tests that are run serially e.g., one after another, instead of in parallel. These tests will become exponentially slower when slowness and instability arise in any of them.
We want to avoid “feedback latency” and “feedback pollution”.
- Feedback pollution is when the clarity of the feedback you’re receiving gets clouded by inaccurate, confusing, slow, or otherwise unreliable information.
- It’s the opposite of high quality feedback.
- This pollution slows down and distorts our assessment of whether or not an action is correct or incorrect and how we should proceed.
- Feedback latency is the delay from when a change is made to when the results are received
- The longer your feedback latency, the longer it’ll take you to learn and make adjustments.
We must be mindful of the human brains limited capacity to process feedback information. When we overwhelm the senses with information, we increase cognitive load. Cognitive load is the total amount of mental effort required to complete a task that involves processing information.
Essentially when cognitive load increases, we can create an “information overload” that increases our likelihood of making mistakes and interferes with our ability to complete a task.[3] By minimizing the amount of feedback pollution and low quality feedback we expose our software developers to, we lower the amount of cognitive load for them to process and understand this feedback and enable them to make better decisions.
Technical Practices That Enable High Quality Feedback
Audit Tests for Consistency, Relevancy and Accuracy
- Periodically review tests for consistency, relevancy, coverage, and accuracy.
- Refactor them when issues are discovered to reduce technical debt.
- Maintaining “code hygiene” in your tests and build scripts reduces maintenance burden.
- Do it at least twice a year, but it’s best when done continuously.
- Use your best judgement when it comes to how much test coverage is needed.
- Generally, more coverage is better than not enough.
- Try to strike the right balance between enough test coverage to verify the code you want to remain stable continues to work and having too much coverage; which can make contributing and refactoring more difficult.
- Document significant testing gaps until you can automate them away. This doesn’t necessarily need to be exhaustive, depending on the purpose of your application, but it helps when onboarding developers so they know where the “blind-spots” are in the current tests.
- You can document them as testing “stubs” that get skipped until you automate them later but are still reported somewhere for review.
- Test code is code. It should be linted, follow similar code review processes, best practices, and conventions like your production code.
- If you need to lint a shell script, which is pretty typical for build scripts, you can use shellcheck.
- Watch out for “evergreen” tests, which are tests that never fail even when they should. Tests that always pass give false confidence. Try to break something in your application and make sure your tests fail.
Run Checks and Tests Frequently
Run linting checks and unit tests continuously while developing e.g., you can set up a file watcher that will look for changes in a specific directory and will automatically execute your linting and test running commands when a change is detected. Example of watching for file changes in Javascript and Mocha
Do a frequent build of your tests against the latest “blessed” branch or a known good version of your software.
- Since these tests should be passing against that version, any failures are probably issues with the tests themselves.
- Test result flakiness happens with both unit and integration tests, although it should happen much less frequently with unit tests.
Get a daily baseline of test results. Run a build of your tests in the pipeline early in the day, ideally a few hours before most people start. This gives you:
- A recent result baseline to compare any failures to.
- The chance to pro-actively address any new stability issues that arise.
- A useful way to keep track of results over time, which can help you spot trends.
Consider rebuilding integration tests that touch many components automatically up to 3 times.
- This can help with the occasional flake but be wary of over-relying on this technique since it could hide some potential instability that you need to address.
Monitor Test Results for Health
Health consists of the test runtime and stability. Monitor for indicators of instability and slowness. To do this, track information that helps you answer questions such as:
- How often does a test pass and fail?
- How long does a test take to run?
- How long does it take to run on average? Is the most recent result faster or slower than the average?
- Based on the test type: unit, integration or acceptance
- What is the average runtime?
- What is the average stability?
- Make results visible in an IRC/Slack room or email. A dedicated #project-ci chat room or email list is useful if things get too noisy. Pro-actively sending this information somewhere visible is preferred to forcing people to dig for it or discover it on their own.
You may want to consider storing results for a significant period of time that will allow you to spot trends. You could store these results in a database that you create and manage for you to query and alert on. If you want something simple and use Jenkins, a plugin like the Test Stability Plugin is a good start.
Triage, Fix or Remove Slow and Unstable Tests
Access to an engineering teams feedback loop is a privilege, not a right. It’s a privilege that must be maintained
Set stability targets with service level objectives (SLOs) you can use to indicate when tests are becoming too unstable. This will help inform us what a tolerable level of instability for a test is. Tests that touch many components will occasionally fail or perform slowly.
- Unit tests should pass over 99% of the time and flake less than 1% of the time. Each unit tests should take less than 5-10 seconds to run.
- Integration tests should pass over 90% of the time and flake less than 10% of the time. Each integration test should take less than 3-5 minutes to run.
- The team should promptly deal with unstable or unreliable tests to avoid “feedback pollution” since it diminishes trust in our other tests.
- If you decide to skip or remove a test, consider the risk/reward when temporarily reducing that test coverage. Ensure the team is aware of missing coverage and address it accordingly.
Provide Contextual Failures
Make it clear if its a developers change that broke a test or if it’s the test itself that’s broken.
- Failing test names should hint as to where something is failing.
- Exceptions should provide context about what type of failure it is.
- Is it a dependency that failed to load?
- Did an API call timeout?
- Did a test dependency not get set up correctly?
- Run “pre-” and “post-” test execution checks
- Run checks on test scenario dependencies, including data expectations, before executing the test body and after doing the teardown.
- Pre-execution checks can be done in the “before each” or “before all” in the test setup. Fail early if an issue is detected.
- Post-execution checks can be done in the “after each” or “after all” after the test teardown. Make sure cleanups happen here to ensure a “clean slate” is maintained and the results of the cleanup are logged.
- Tests written with languages and tools developers already use minimizes the cognitive load for them to contribute. It also makes stack traces more natural for them to read and test configuration more straight-forward.
Published: 2018-10-14
Credits
Thank you to Ashima Athri for the review of this article and giving me valuable feedback to improve it! You can check our her blog on computer vision and machine learning here: blog.immenselyhappy.com
Feedback
You can submit feedback about this article here in Github or tweet me @build_wrangler
References
[1] Tracer-Bullet Development, Andy Hunt https://growsmethod.com/practices/TracerBullets.html
[2] Henrik Kniberg, Mattias Skarin; Kanban and Scrum - Making the Most of Both https://www.infoq.com/minibooks/kanban-scrum-minibook
[3] Cognitive Load Defined Cognitive Load